基于互联网大数据的交通拥堵短临预警模型研究
原文刊载于2021年智慧交通杂志电子刊7-8月合刊。
近年来,城市机动车保有量迅猛增加,而道路建设相对滞后,道路交通拥堵问题仍是主要的交通管理问题。以往通过群众报警、民警巡逻、视频巡查发现交通拥堵的时效性较差,而传统的拥堵分析模型主要针对的是过去的或当前的交通状态,缺乏对即将发生的交通状态的预判,制约了指挥员的决策水平和决策效率。因此,为了减少城市交通拥堵,提高出行效率,建立一个针对将来时的拥堵短临预测模型显得尤为必要。拥堵短临预测模型的广泛应用,微观上可实现对各个拥堵节点实时预警,掌握路段交通流运行状况的实时状态,宏观上更全面感知路网通行情况,进行实时交通动态诱导和有前瞻性地指挥调度,为系统解决城市交通问题提供有针对性的对策。

一、建模方案
(一)建模目标
选取福州城区228个重要路段为预警节点,接入互联网高德路况大数据,从高德路况大数据中找出预警节点及关联路段拥堵状态为拥堵或严重拥堵的时间点,计算出拥堵时间点往前60分钟至30分钟的历史拥堵速度向量,同时计算出当前时间点往前30分钟的实时速度指标向量,依据这两个向量计算拥堵因子并根据时间距离、空间距离加权计算得到30分钟后的拥堵短临预警风险,并进行分级展示。实现科学预测时空路网交通拥堵程度,充分掌握时空路网上未来各时刻不同空间位置的交通拥堵状况。
(二)模型数据
本模型融合了互联网高德路况数据以及交警部门重点管理的228个预警节点属性数据,其中,高德路况以2分钟为周期传输,全市生成道路状态记录约5900万条/日左右。具体内容如表1所示。
表1 模型数据来源和获取方式 | ||
数据类型 | 数据来源 | 数据获取方式 |
高德路况数据 | 高德数据 | 接口 |
预警节点属性数据 | 交警 | 数据 |
(三)技术路线
以Hadoop作为数据支持平台,以Nifi作为互联网数据的获取方式,采用列式存储(CL-B,Column-based)的方式对高德路况等数据存储,按照列为基础逻辑存储单元进行存储,列中的数据在存储介质中以连续存储形式存在,对各列的运算并发执行(SMP)。实时数据计算采用低延迟、可扩展、高效率的Storm流式处理框架。离线数据计算选取专用于海量数据计算的Spark计算框架,提供分布式数据集群计算环境采用分布式查询引擎impala、spark实预警节点属性数据和高德路况数据的关联碰撞分析,实现分析结果的毫秒级响应。
(四)数据质量评估和预处理
1.质量评估:高德路况数据约5900万条/日左右,模型基于数据完整性检测、数据准确性检测、数据有效性检测、数据一致性检测等规则,对新增的数据进行数据质量检测。
数据完整性检测:描述数据信息缺失的程度,是数据质量中最基础的一项评估标准,主要为数据信息记录缺失和字段信息记录缺失。1、对于数据信息记录缺失的检测,通过对比源库上的表数据量和目的库上对应表的数据量来判断数据是否存在缺失。2、对于字段信息记录缺失的检测,选择需要进行完整性检查的字段,计算该字段中空值数据的占比,通常来说表的主键及非空字段空值率为0%。空值率越小说明字段信息越完善,空值率越大说明字段信息缺失的越多。
数据准确性检测:描述一个值与它所描述的客观事物的真实值之间的接近程度,数据记录的信息是否存在异常或错误。例如数据速度字段取值均为0,此时信息存在异常。
数据有效性检测:描述数据遵循预定的语法规则的程度,是否符合其定义,比如数据的类型、格式、取值范围等。有效性规则包括类型有效、格式有效和取值有效等。类型有效检测字段数据的类型是否符合其定义。例如数据重复、某个必填字段为空。
数据一致性检测:数据是否遵循了统一的规范,数据之间的逻辑关系是否正确和完整。例如速度较高时,道路状态字段显示严重拥堵,此类不一致情况。
数据检测结果如表2所示,数据评估结果:数据质量较好。
表2检测结果
检测问题 | 评估结果 |
数据完备性 | 99.98% |
数据准确性 | 99.92% |
数据有效性 | 99.95% |
数据一致性 | 99.93% |
2.预处理
针对上述数据质量问题,检测数据异常值,去除数据异常值,删除重复值,保证数据的合理性;填补缺失值,根据数据集中记录的取值分布情况填充缺失值;进行数据标准检查、修正以及数据一致性转换。
(五)建模步骤
1. 步骤1:数据处理并构建时间框架。
1)数据处理
a.定义预警节点集合P与高德数据集合T。
预警节点集合P(p1,p2,p3,…,pk,…,pl),其中l为预警节点总量;预警节点k的路段ID集合Rk(rk1,…,rkj,…,rks),其中,s为预警节点k的路段ID总量;第k个预警节点第j个关联路段ID的路况数据集Tkj{Tkj1 ,…, Tkji,…, Tkj},其中Tkji为多维数组(pk,rkj,ti,sti,wi,vi)。即{预警节点序号,预警节点相关路段ID号,数据时间,拥堵状态,数据星期属性,数据速度}。
b.构建数据切片。
由于高德数据传输时间存在误差,为保证数据全面性,以6分钟为窗口,将每一小时路况数据集Tkj划分为10个切片,切片时间Tt记为每个窗口开始时间。定义第k个预警节点j个关联路段ID的路况数据Lkjt{pk,rkj,tt,stt,wt,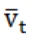 },同时获取每个切片的平均速度
},同时获取每个切片的平均速度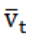 以及拥堵状态stt。
以及拥堵状态stt。
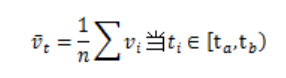
其中,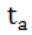 为切片起点时间,
为切片起点时间,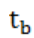 为切片终点时间,n为每个切片时间内的数据量,
为切片终点时间,n为每个切片时间内的数据量,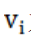 为第i条路况速度,
为第i条路况速度, 。
。
后期模型计算根据Lkjt进行计算。
2)构建时间框架
由于路段周一至周日居民出行目的不同、方式不同,所以在进行拥堵预测时,需将不同时间属性进行关联参考。模型以7天为一个周期,将不同星期属性的数据分区,构建拥堵分析时间框架{星期一、星期二、星期三、星期四、星期五、星期六、星期日}。
2.步骤2:基于历史平均法模型计算拥堵速度向量
1)提取多个周期内同一时间框架拥堵节点(pk)关联路段ID(rkj)的拥堵发生时间,即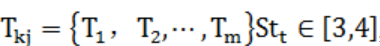 , m为拥堵次数。
, m为拥堵次数。
2)设置历史参考路况数据与拥堵的时间距离,构建历史时间速度矩阵S。
对每个拥堵记录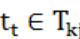 ,分别提取距拥堵时间之前[30,36)分钟,[36,42) 分钟,[42,48)分钟,[48,54)分钟,[54,60)分钟五个范围的路况数据,并构建时间速度矩阵。
,分别提取距拥堵时间之前[30,36)分钟,[36,42) 分钟,[42,48)分钟,[48,54)分钟,[54,60)分钟五个范围的路况数据,并构建时间速度矩阵。
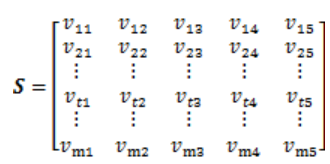
3)根据时间速度矩阵S,利用历史平均法模型,计算预警节点的拥堵速度指标向量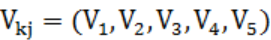 。以
。以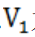 为例:
为例:
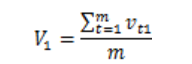
3.步骤3:计算实时速度指标向量
1)构建实时速度指标向量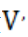 。对每个实时高德路况数据,分别提取距当前时间 [0,6)分钟,[6,12)分钟,[12,18)分钟,[18,24)分钟,[24,30)分钟,五个时间距离范围的速度数据。
。对每个实时高德路况数据,分别提取距当前时间 [0,6)分钟,[6,12)分钟,[12,18)分钟,[18,24)分钟,[24,30)分钟,五个时间距离范围的速度数据。
记为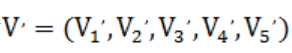 ,其中,以
,其中,以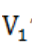 为例,表示距当前时间为0-6分钟的时间距离的切片平均速度。
为例,表示距当前时间为0-6分钟的时间距离的切片平均速度。
4.步骤4:基于时间距离权重与空间距离权重,预测预警节点未来30分钟的拥堵概率。
1)时间距离权重
根据预测时间与当前时间的时间距离对拥堵影响的差异,设置时间权重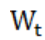 。
。
表3时间距离权重
时间距离 | 权重 |
6 | 0.333 |
12 | 0.267 |
18 | 0.200 |
24 | 0.133 |
30 | 0.067 |
2)拥堵因子计算
根据实时速度指标向量 与拥堵速度指标向量
与拥堵速度指标向量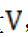 ,模型提出拥堵因子,表征拥堵相似性,定义
,模型提出拥堵因子,表征拥堵相似性,定义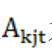 为拥堵节点k关联路段j的拥堵因子。
为拥堵节点k关联路段j的拥堵因子。
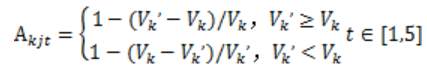
3)通过加权滑动平均法,对不同时间距离的拥堵因子进行加权计算,得到拥堵概率预测。
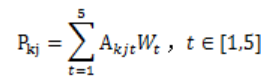
另外,由于预警节点会受多个路段的拥堵影响,所以模型设置空间权重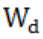 ,预警节点与路段的关联,根据影响拥堵的重要性分配空间权重
,预警节点与路段的关联,根据影响拥堵的重要性分配空间权重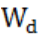 。以魁岐隧道(东往西)节点为例,空间权重如表4所示:
。以魁岐隧道(东往西)节点为例,空间权重如表4所示:
表4空间距离权重
预警节点 | 预警节点ID | 对应高德路段ID | 权重 |
魁岐隧道(东往西) | 1 | 5886794240184289769 | 0.6 |
魁岐隧道(东往西) | 1 | 5886794240184887432 | 0.4 |
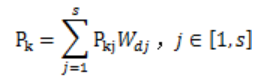
(六)模型结果展现
1)模型计算结果
模型计算结果为每个预警节点的拥堵概率,范围为[0%,100%]。将预测数据与实际高德路况拥堵状态比对。高德路况拥堵时拥堵概率预测结果大部分位于70%-80%区间,因此选择70%作为评价拥堵高低风险的阈值。
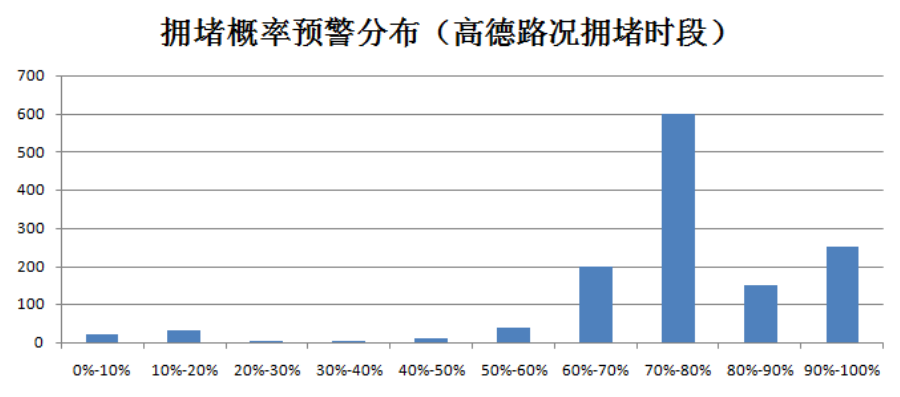
根据拥堵高低风险的阈值(70%)判断拥堵风险分级结果,结果为整数[1,2],1为低风险,2为高风险。拥堵概率在[0%,70%]时对应的拥堵风险分级结果为1,表示该路段未来半小时拥堵的可能性较低;在[70%,100%]时对应的拥堵风险分级结果为2,表示该路段未来半小时拥堵的可能性较高。模型输出如表5所示:
表5模型输出数据
预警节点名称 | 预警时间 | 拥堵概率 | 拥堵风险 |
尤溪洲大桥南往北 | 2021-6-1 00:00 | 10% | 1(低风险) |
尤溪洲大桥南往北 | 2021-6-1 07:30 | 75% | 2(高风险) |
尤溪洲大桥南往北 | 2021-6-1 08:00 | 90% | 2(高风险) |
尤溪洲大桥南往北 | 2021-6-1 09:00 | 50% | 1(低风险) |
2)模型结果准确率
取预测的拥堵风险与实际高德路况拥堵状态进行比对,低拥堵风险对应高德路况畅通状态、高拥堵风险对应高德路段拥堵状态,准确率为预警节点预测状态与实际交通状态一致的概率。经统计,模型准确率分布区间为[80%,98%]。
准确率=预测状态与实际拥堵状态相同的次数/总预测次数
以尤溪洲大桥南往北节点为例,拥堵概率预测曲线与高德路况数据比对的24小时分布如下图所示,其中蓝色趋势为高德状态、黄色趋势为预测曲线。所示准确率为86.08%。
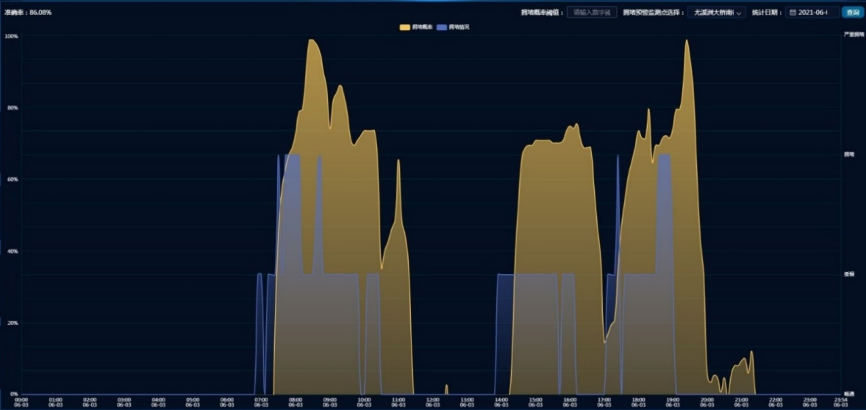
3)模型结果应用情况
模型结果应用于福州交通综合态势系统,结合PGIS地图实时展示各个拥堵节点预测交通状态,红色标记为拥堵高风险,绿色为拥堵低风险。
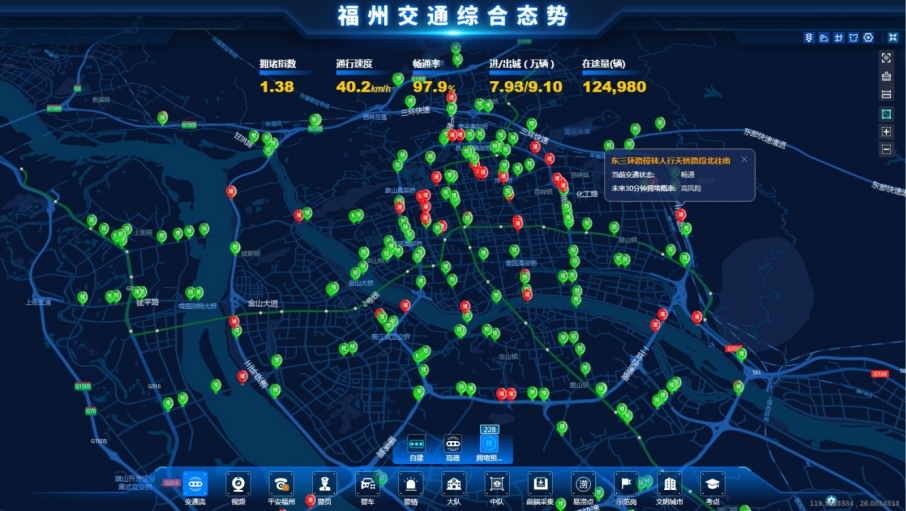
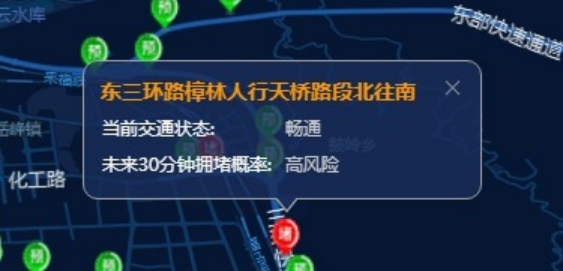
二、实战应用成效
模型计算分析了城区228个拥堵预警节点,实时预测各个预警节点拥堵风险。通过模型应用,福州交警形成新的排堵保畅工作机制:拥堵高风险预警→根据节点预警提前部署警力→强化铁骑巡线→快速就近排堵。根据道路预警信息提前落实拥堵预警防治机制,及时处理突发事件并进行交通诱导,提高了道路通行效率,降低了城市道路交通事故发生率。模型应用部署三个月以来,发布拥堵高风险预警2万余次、日均200余次,根据预警结果指令调度骑警部署在拥堵高风险路段上下游节点开展预防性交通保障6000余次、日均50余次,排堵效率提升了30%,交通拥堵程度平均下降了25%。
三、推广应用前景
该模型具有可推广前景:一是交通管理方面:对未来的交通状态进行预测,建立拥堵预警防治机制,让交通管理部门发现拥堵由被动变为主动,实现交警管理指挥工作的情报主导、精确打击、精准防控。二是交通规划方面:掌握全市交通堵点时空分布情况,发现道路规划中不完善的部分,为路网更新、交通决策、动态交通诱导和城市交通综合评估等方面提供决策支持,具有非常重要的应用前景。三是数据方面:本模型数据基于互联网公司数据,可根据实际情况替换为交通流检测设备检测结果数据及相应的评价指标,具有一定普适性。
作者简介:
1.尤晋闽:福州市公安局交通警察支队交通指挥中心副主任
2.邱彤洲:福州市公安局交通警察支队交通指挥中心科员
3.陈奋翔:福州市公安局交通警察支队副支队长
4.范力戎:福州市公安局交通警察支队交通指挥中心主任

VIP项目信息
- 公路信息化之800万以下中标项目汇总(10.16-10.31)
- ITS114 智能交通市场每周千万项目(10.11-10.17)
- ITS114 智能交通市场500万以下项目(10.11-10.17)
- ITS114 公路信息化市场每周千万项目(10.11-10.17)
- ITS114 安防市场每周千万项目(10.11-10.17)
- IOV114 运输信息化近期招标项目一览(10月NO.1)
- ITS114 智能交通市场每周千万项目(9.29-10.10)
- ITS114 智能交通市场500万以下项目(9.29-10.10)
- ITS114 公路信息化市场每周千万项目(9.29-10.10)
- ITS114 安防市场每周千万项目(9.29-10.10)
