低价值密度下公安交管大数据应用实践
10月21日,中国智慧交通管理联盟第五次年会-交通管理大数据技术应用论坛在线上举行,公安部交通管理科学研究所五部副主任黄淑兵就《低价值密度下公安交管大数据应用实践》进行分享,本文为演讲速记,未经本人审核。
黄淑兵:大家好,今天我给大家汇报的主题是低价值密度下公安交管大数据的应用实践,大家看到题目可能会有一个疑问,什么样的交管数据价值密度比较低。今天分享的交管大数据价值,是指在大数据业务应用中可以发挥的作用。
大数据的5V特征
有说是四维特征,有说是五维特征,实际上大同小异了。大数据的第一个特征,数据量非常庞大?那么大到什么样的程度才算大呢?一般来说是要达到Pb级量级才能认为是大数据。从严格意义上来说,机动车驾驶员静态数据还不能算是大数据,不能说是严格意义上的大数据,今天主要汇报的内容是公安交管集成指挥平台,通过路面前端卡口设备采集到机动车通行轨迹数据,这个数据量非常庞大。目前我们汇聚的数据量已经达到了万亿级别,每天的增量大概是12.5亿左右,毫无疑问,这是一个庞大的数据量。
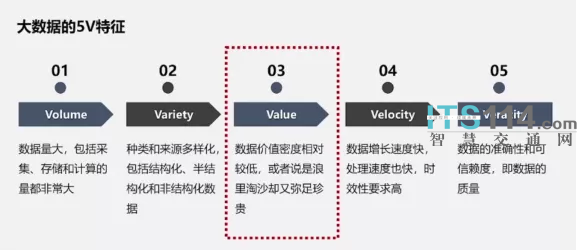
大数据的第二个特征是价值特征,就是说价值非常庞大,是针对于总体价值来说的。还有一种说法说是大数据的价值密度实际比较低,数据量非常庞大,但单条数据价值相对比较低的。一个说大,一个说低,实际上并不矛盾,一个是从总体出发,一个是从单条数据可以发挥的作用而言,大家关注的点不一样。现在,大数据发展应用到一定阶段以后,又开始考虑大数据到底能够发挥多大的作用?数据价值到底能到一个什么样的程度?
交管大数据的价值密度低体现在哪里
有很多因素。首先从数据质量的角度出发,交管大数据是指通过道路上各种交管设备传感器采集到的数据,数据质量并不高。根据《道路车辆智能监测记录系统通用技术条件》标准提出的车牌识别准确率要求,白天识别准确率不能低于95%,夜间识别准确率不能低于90%。一般情况下,产品检测时是按照理想的光线和跟车环境来做检测,成像的角度数,图片的清晰度,包括测试场景都比较单一,测试的时候产品能达到这两个指标,问题不大。
但实际上卡口是安装在路面上,识别就有些问题。比如像首汉字的识别,很多设备的首汉字识别错误的现象还是比较严重,比如像“湘”很容易被识别成“浙”和“冀”,比较容易混淆。包括一些非均衡的号牌,经常会被误识别,甚至有些车的车身广告数字和条纹,都会被误识别成车牌。还有一些容易混淆的字母或数字,比如像D和Q很容易会被识别成0,P容易被识别成F等。基于目前的数据情况,其实卡口设备的识别准确率在实际环境中是比较低的,识别准确率低,也就意味着采集的数据跟实际情况不相符合。
前一段时间,我们选取了条件比较好的高速公路路段上功能相对单一的、拍摄单个车道的卡口所采集到的、能识别车牌的图片进行分析,发现大车的车牌识别准确率目前只有80%,小车的识别准确率是87%。表面上看起来距离行业标准比较接近了,但这只是已经抓拍和识别后的车牌分析,还有大量未被识别、无号牌的抓拍图片,也还不包括未被卡口抓拍到的车辆。也就是说,目前卡口的车牌抓拍识别率实际上不足70%。曾经我们拿过卡口抓拍到的车牌数据,跟交通运输部重点营运车辆联网联控系统平台的GPS车辆轨迹数据做了一个碰撞分析,但两边数据能重合的,大概也就百分之五六十左右。也就是说,尽管我们现在拥有了上万亿条的卡口数据,但只有70%不到的数据是准确的,还有1/3左右的数据不可识别或者识别错误,这会带来什么影响?
举一个简单的例子,比如这个模型是一个我们用来分析从事非法营运车车辆的模型,模型比较理想,也能够发挥一些作用。
模型的原理比较简单,频繁往返于机场、客运车站等场所的车辆,比如面包车、小客车等不具备营运资格的车辆,就可以被预警为疑似非法营运车辆。在理想的数据情况下,只要是从事非法营运车辆的嫌疑车辆,基本都能被发现。但在实际应用中出现了一些问题。比如真正从事非法营运车辆的车辆号牌根本就没有被识别到或者识别错误,系统无法识别也就无法预警,就会出现漏报。还有将具备资质的营运车辆识别成其他车辆的号牌,系统分析就会造成误报。不管是哪种情形,这两种情况都会对实际应用造成较大影响。
第二个价值密度低的表现是覆盖面不均衡不完整。
现在全国所有卡口都要求接入到公安部交通管理集成指挥平台里,实际上还有大量的卡口还没有接进,因此就导致数据覆盖不全。另外,道路上的卡口设备没有达到路段100%覆盖。
数据覆盖不全,就可能导致分析结果的偏差。比如说分析某高速公路的车流量什么时候最大,什么时候最小,什么时候哪些路段车流量最大。若是路段中间卡口设备空缺,不管怎么分析,都会出现错误。
根据《2020年加强重要点位交通监控设备联网接入和运维管理工作方案》要求年底前,国家高速公路服务区、收费站卡口联网率达到60%以上。但到目前为止,高速公路服务区的卡口联网率只有43%,收费站的卡口联网率更低,只有21%。当然这里有很多的因素,设备不是交管部门建和用,采用交通运输部的设备可能通讯协议和数据格式,和交管部门可能会有差异,这些设备就没有被接进来。有些服务区,可能根本就没安装卡口,这样就做不到全覆盖。
如果做不到全覆盖,对大数据分析有什么影响?可以看一下比较典型的专项大数据案例。很多时候我们拿大数据和传统的民警经验来做比较,比如以往要组织一些专项行动,更多靠一些老民警的经验来实现,有了大数据以后,就可以依靠数据来实现辅助决策。
举个例子。我们通过卡口识别车牌,通过车牌信息在车驾管数据中了解到车辆基本信息,包括车辆类型,年限,荷载人数或者吨数等,这是单条数据。积累了一定量的数据以后,就能够分析出来在哪些道路、哪些时段上,到了报废期限仍上路的大货车比较多,从而有助于决策,是否开展一次针对于大货车逾期未报废的专项整治行动?
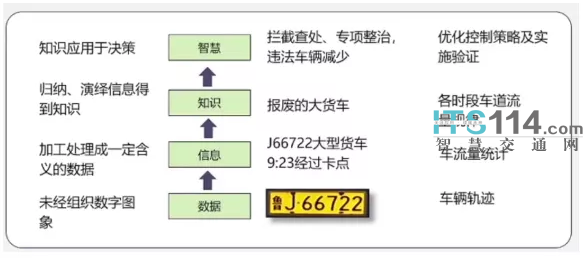
专项行动有没有取得效果,也是根据大数据的分析和运算来复盘,如果逾期没报废的车辆确实减少了,专项行动就可以结束了,而不像以前没有数据支撑,不知道要开展几次专项行动执法,才有效果,只能固定排班,浪费警力。但如果某一条路没有一个卡口接进来,数据分析就不完整,有可能这条路上逾期未报废却上路通行的车辆最多。
所以如果数据不全面,就很可能做出误导性的决策。虽然模型很好,但实际上因为数据没有做到全覆盖,数据分析结果就出现问题。为什么会出现这样的情况?我们也简单做了分析,从技术层面来说,现在公安交通集成指挥平台接入的卡口设备,大概有5.1万套是三年前备案,此外,即便是三年前备案接入,设备实际的建设应用可能更早,早期设备的技术条件还没有目前这么先进,当时用的识别技术、算法跟目前的技术完全不是一回事。
这些卡口的成像条件也没有现在这么好,因而可能造成识别错误。比如这张抓拍图片,车身上喷涂的顺丰快递专用服务电话号码比车牌本身要清晰,正好也是5个数字,卡口就容易将这个电话号码识别成号牌。比如这种农用车,因为样本数据少,更多的被识别成小型汽车。比如这两年开始规模上路的新能源车辆,不少卡口在安装时,还没有新能源号牌,也就不具备识别的能力,很多前端设备又没有及时的升级,没有更新识别算法,因此这些新能源号牌通过此类卡口后,基本上车牌数字会少一位。
还有很多摩托车和电动自行车卡口基本识别不了,甚至有些摩托车和非机动车抓拍照片压根就没有传到公安交通集成指挥平台里面去,这样就会造成很多数据的错误和缺失。
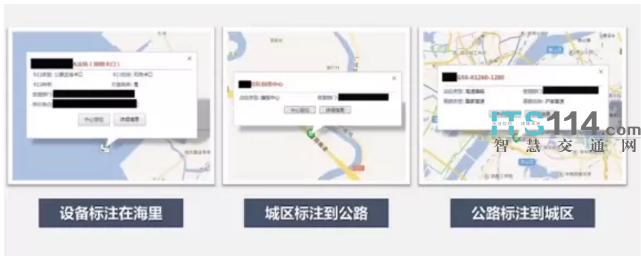
从管理角度来看,还有很多卡口位置的地图标注存在问题。因为很多模型会根据两个卡口设备间距离,从而推算出车辆通行的速度。但这些卡口位置的地图标注都是人工标注的,人工标注就可能存在误差。比如有相当一部分设备,根本没有标注在路上,甚至标到了河流、湖泊、山脉上。还有一些比较难以发现,比如城区一个卡口被标注到城际公路上,也就是位置错标。这样的数据,如果拿过来做数据分析,输入业务模型,就会存在问题,也就不能得到一个有效的价值信息。
还有,对前端设备的运维,可能也没做到位。比如被树叶被遮挡,强烈反光,补光不足,以及设备安装角度出现偏差,就没办法较好的采集到车牌数据并识别。
价值密度低的影响
通过前面的分析,可以看出目前公安交管大数据主要还是通过车辆轨迹数据实现各种目标。数据质量不高会带来什么影响?目前的算法、技术走到了前面,即便数据存在问题,但业务模型仍可以产生一些效果。技术解决了能不能的问题,后面能不能用好,就依赖于基础的数据质量。也就是说,现在解决了从0到1,下面就是如何从1走到100。
要实现这个目标,要解决两个问题。有两个很大的问题需要去解决。
第一个鸿沟,技术和业务的鸿沟,技术是为业务服务的,技术能不能用于业务,中间有一个很大的跨度需要去通过。举一个简单的例子,我们的技术指标可以达到很高,通过各种算法的一个训练优化,使准确率达到99%。比如说套牌车的识别,套牌车是怎么识别的呢?就是通过卡口电警等设备识别出车牌后,再将车辆特征与车驾管的登记数据进行核对,不符合的极可能是套牌车。假设一个城市里套牌车的比例是万分之五,10万辆车里可能有5辆套牌车,但识别准确率是99%,那可能1万辆车里面有100辆被识别出疑似套牌,但真正的套牌车实际上只有5辆。所以,即便准确率达到了99%,但对于应用人员来说,能发现套牌车的准确率只有5%。目前技术手段虽然已经很成熟,但要真正的投入业务应用,还有很多功课要做。
第二个鸿沟就是理论和实际的鸿沟。理论上模型很完美,但实际应用时,又会发现各种各样的问题。简单举两个例子,比如车辆限尾号通行,怎样科学合理的制定限行政策和措施,要不要限行?什么时段限行?应该限哪些车?目前多是组织去北京上海深圳杭州广州等地考察一下,但实际上不同城市的交通流车辆类型和通行规律,是不同的,借鉴作用有限。
若是通过数据来,比如说通过这个城市的卡口采集了很多数据,通过数据分析发现车流量在什么时段最大,由哪些类型的车辆组成,本地车和外牌车各有多少,哪些是长期行驶,哪些是短期通行,哪些车辆通勤距离很长,哪些很短?通过数据的预演推算,就可以模拟制定出一套比较合理的限行政策。
之前我们经常会拿这个来举例,但发现很少有地方拿这个数据来作为决策依据。理论上是可行的,但目前的数据质量,包括准确率、覆盖面都还达不到实际应用的要求。如果数据质量不高,反过来还会产生负面的影响。
再举个例子。现在有很多地方在提,根据卡口采集的车辆通行轨迹特征对城市出行做一个画像。包括车辆基本信息,每天什么时间出行,通行距离多少,通行强度是多少……但多停在理论阶段,因为能够满足出行画像要求的车辆,可能只有10%左右。因为很多车采集到的轨迹数据很少,如果只有几条或者十几条轨迹数量,就达不到画像的要求。即便数据量达到了一定的要求,但因为数据质量比较低,对该车辆的出行画像准确性,也没有办法验证。
可以简单的总结一下,目前大数据处理分析技术已经非常成熟,但是交管大数据的应用还远远没有跟上。技术的研究发展和推进,主要由一些企业和高校在研究,技术上没有问题。但在应用的过程中,就涉及到真正的数据应用。
一般一些模型训练的数据量比较少,很多的数据还是模拟的。有些地方为了避免模拟数据带来的问题,会挑一些城市的真实数据输入,但即便是真实的数据,也不能代表全国的城市。
所以说,在理想的数据环境下,模型已经很成熟,没有问题,但投入到应用后,你就发现不同城市的情况是不一样的。前一段时间我们也在调研,发现很多地方都上了很多大数据应用模型,也确实收集了很多的数据,但这些模型真正应用上,还是很少。
没有常态化的应用,主要还是因为两个鸿沟,一个是技术和业务的的鸿沟,一个是理论和实际的鸿沟。
低密度价值下大数据应用常用方法
今天汇报的主要内容,就是如何在现有情况下,来更好的实现交管大数据应用。先回顾一下标准的大数据处理流程,一般通过几个步骤,先是采集数据,采集完后是数据清洗,清洗完后再对数据做分析和挖掘,最后对数据分析挖掘的结果做应用。但根据我们长时间的经验发现,数据清洗不是一个预制的动作,而是一个从前到后由始至终都需要的操作,就是说在数据采集过程中需要清洗数据,数据分析挖掘时也要清洗数据,甚至最后的应用过程中,还是需要清洗数据。目前数据质量就摆在面前,整个应用过程都离不开数据的清洗和数据的处理。
数据清洗和处理有哪些方法?简单列了几个,和大家分享一下。
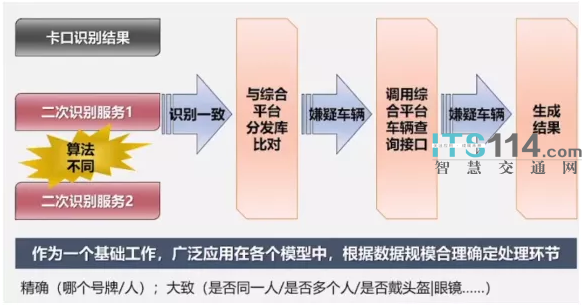
第一种方法是二次加工,2014年我们就开始做。通过二次识别以后,识别的结果再跟卡口所采集数据做一个比较,如果结果是一致的,就可认为数据是可用的。
如果对比对结果不满,再来一个二次识别,因为二次识别的算法可以有多种不同的算法,采用不同的算法交叉验证,验证完以后,将可信度更高的数据拉入后续应用。二次加工方法也不是一个单独的应用,可能会跟其他的数据加工方法结合在一起,也不是说在每个环节都适合。二次识别需要对图片做特征的提取,算力消耗比较大,时间也相对较长。所以这个过程一般不会放在第一环节,第一环节经过初步的加工初筛以后,得到一个数据量比较小的数据集以后,再采取二次加工的方式。
二次识别除对机动车号牌进行识别以外,还可以对驾驶人做二次识别。很多模型里面会对同一路程中,驾驶员是否同一个人进行识别,非机动车驾驶员是否戴了头盔等进行识别,并不要很精确。当然有些缉查需要知晓驾驶员身份,包括身份证号码、驾驶证信息等。
怎么判断一个车底有没有更换驾驶员,主要应用场景是大客车和重载货车,一是是否符合准驾资格,二是是否有疲劳驾驶的嫌疑。通过大数据分析得出嫌疑车辆,如何确定到底有没有换驾驶员?只要把主驾驶和副驾驶两人的特征来提取出来,再交叉验证一下,两人有没有换座位,主驾驶位上是不是同一个人就可以了,并不需要知道驾驶员是谁,甚至都不需要人脸信息,只要提取大概特征,比如对衣服样式和颜色进行提取然后分析。
第二个方法是叫条件过滤。
这可能是在大数据处理中最常用的一个方法,例子也可多举几个。第一个是城市套牌车分析,原理也比较简单,同一个号牌的两辆车,不大可能再一个很短的时间内,出现在两个不同的地方。如果出现,某一辆车可能套牌嫌疑车。原理比较简单。很早以前就提出来了,但当时数据的处理能力还不够,还是比较难实现,但现在有了大数据技术以后,很容易就能实现。
但在应用的过程当中也发现了问题,比如原始数据中2100个卡口,7天的抓拍图像数据总量汇集达到了1.66个亿车辆数据。
对这些数据输入模型然后运算,结果是有46.9万对的嫌疑车同时出现了两地。用常识想也知道,不可能有46.9万套牌车,为什么会出现这样的数据结果?主要还是因为数据质量。比如如何界定异地,首先会用到两个卡口之间的位置。如果本来两个卡口距离很远,但被人为的标注到比较近,抓取车牌后也就可能被认为是套牌嫌疑车。此外就是号牌识别错误。比如一个是Q一个是0,但都被识别成0,也会被认为是同一个号牌。怎么办?

所以要用条件过滤,比如刚提到的同一个卡口,本来是距离很远,误标注到一起以后就被认为是嫌疑套牌车。怎么过滤呢?就把符合这样条件的卡口所采集到的数据,全去掉。通过筛选以后就剩下2万对嫌疑车,基本比较接近实际情况,但还是有号牌识别错误的情况。
号牌识别错误怎么解决?前面也说了,可以通过二次加工对吧?采用另一种算法二次识别一下,这样的数据才认为是嫌疑套牌车的数据。通过二次识别后,剩下2000多对车有套牌嫌疑。
第二个例子是黑校车识别。原理也不复杂,就是筛选出那些在上学、放学时段,经常在学校附近出现但平时又不出现的面包车。通过大数据运算以后,确实能够筛选出符合这样特征的车辆。
当然同样我们也发现有些车辆并不是面包车,只是因为号牌识别错误,被错认为是面包车,这时同样可以增加图片二次加工环节,来过滤数据。
此外,黑校车一般会在车厢内塞很多学生,可能存在某几辆面包车每天给学校去送货,也会每天在这个时段出现,这时候再加一个前排人脸识别,只要识别出车前排坐了几个人。通过二次加工以后,就能初步判断是否有非法营运的嫌疑。除此之外,通过长期跟踪发现,有一些车辆也会被误识别,比如一些学校周边的家庭,有两个小孩,每天送小孩上学放学,这也要用到一个过滤,比如说一些白名单的集合,在分析的结果中剔除。
还有一些其他的过滤方法,比如像按轨迹次数过滤,轨迹天数过滤等。前面说到对车辆出行进行画像,首先轨迹的数量要达到一定的数量值。比如可以设定一个阀值,出行轨迹条数一定要超过多少条,一个月内通行天数要超过多少天,符合这样条件的,才给车辆去做出行画像,这也是条件过滤。
第三个方法是多元数据的融合。
用一维的数据来分析,也没有办法确定分析结果的准确性,也没有办法去过滤,但可以通过另外的数据来跟现有的数据做交叉融合,验证之后来确定结果的准确性。
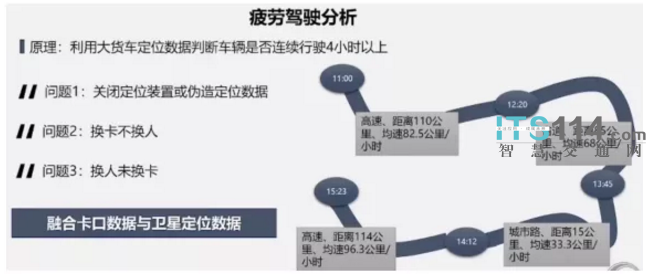
比如疲劳驾驶的数据分析。此前是通过车辆的定位轨迹数据,连续行驶4个小时以上就认为存在疲劳驾驶的嫌疑,但模型也是比较简单、理想,在运用的过程当中就发现很多问题,比如有些车辆没有正常开启GPS装置,或者上传伪造的定位数据,这些车辆即便有疲劳驾驶的嫌疑,也很难发现。还有一些车辆定位设备正常,数据也上传,发现存在疲劳驾驶的嫌疑,但驾驶人可能会抵赖,说换了人了,但是IC卡忘了换,这个时候也没有充足的证据证明他有疲劳驾驶嫌疑。还有一些是换了卡,但没有换驾驶人,还是同一个人开,这样也很难发现是否疲劳驾驶。
针对这些情况就可以用到多元数据的融合交叉验证,把定位数据和卡口数据做交叉融合,卡口是能够拍到货车前部的照片,这个时间点是哪个驾驶员,如果把这个图片作为证据给驾驶员,驾驶员很难抵赖。
若是换卡不换人,或者关闭设备,这些没有被发现的疲劳驾驶人员,也可以通过算法来做简单的验证。车辆在两个卡口之间通行了多长时间,可以算出行驶速度,如果速度是在100以上或者是80以上,基本可以认定在这两个卡口之间没有停车休息的,一旦休息了满20分钟,行驶速度肯定是达不到80以及100。根据这个原理去累计分析,超过4个小时行驶速度都在80以上,就证明没有休息过,有疲劳驾驶的嫌疑。再拿卡口数据和GPS定位数据来做一个交叉的验证。一方面能认定四小时内没有停车,同时也读不到GPS数据,但车辆是连续行驶,同时又能知道车内驾驶员没有更换,通过这些数据的交叉融合,去提高数据的准确性,如果你是用单一的数据,分析结果是不准确的。
第四个方法是人工干预。
目前的大数据分析还没有达到非常准确、智能的程度,要完全通过算法运算推出来的结果不一定是准确的,所以就需要人工干预,但人工干预也分很多场景,有些是事前人工干预,有些是事后干预,有些是事前事后都需要人工干预,常见的人工干预方法就是人工匹配。
比如要分析一些区间的车辆通行速度,首先得知道哪个是起点,哪个是终点,需要提前人工标注好。比如设定一些参数的阈值,像套牌嫌疑车的分析,区间设置的分析,可以设定一个速度,因为有些卡口的时间不一定准确,算出来的速度可能会有偏差,阀值可以调高一点。
最常用的是人工审核,最终分析的结果还需要人工审核判断,因为很多交管业务应用都会涉及,如果存在交通违法,就可能会涉及到处罚。如果涉及到处罚的话,就要保证数据是准确的,所以基本上每一个业务模型的最后都会有一道人工审核确认的环节。
总结和展望
前面主要是介绍了低价值密度下交管大数据常用的几个方法。简单总结一下,这些应用主要针对数据应用,在这方面下一步主要的工作是深化数据治理,很多数据的清洗、模型的优化、迭代都属于数据治理的内容。另一个工作是需要有更多的数据接入进来,比如保险大数据、事故数据等等,进行多维的交叉的验证。就数据采集来说,加强源头管理很重要。前面说的都是基于现状怎么数据治理,如果加强数据源头管理,保证第一手采集的数据是准确及时无误,就能做更好的应用。下一步我们会组织全国交通监控前端设备的升级和运维保障,并计划组织开展视频专网公安交通集成指挥平台的建设,从而加强前端卡口设备的运维管理。通过AI智能运维,自动检测卡口设备采集的角度是不是准确,数据是不是及时传输等。最后希望通过大家共同的努力,然后能够把公安交管大数据应用用得更好,谢谢大家。

延伸阅读!
VIP项目信息
- 公路信息化之800万以下中标项目汇总(4.1-4.15)
- ITS114 智能交通市场每周千万项目(3.29-4.04)
- ITS114 智能交通市场500万以下项目(3.29-4.04)
- ITS114 公路信息化市场每周千万项目(3.29-4.04)
- ITS114 安防市场每周千万项目(3.29-4.04)
- IOV114 运输信息化近期招标项目一览(4月NO.1)
- ITS114 智能交通市场每周千万项目(3.22-3.28)
- ITS114 智能交通市场500万以下项目(3.22-3.28)
- ITS114 公路信息化市场每周千万项目(3.22-3.28)
- ITS114 安防市场每周千万项目(3.22-3.28)
